

在AutoDL上面编译tritonserver(不使用docker)
- Container OS: Ubuntu 22.04
- CUDA NVIDIA CUDA 12.3.2
- cuDNN 9.0.0.306
- Python 3.10
- Triton Inference Server: 2.43
在autoDL选择合适的显卡和镜像
- 需要选择支持cuda12.3的显卡(这个一般由英伟达驱动决定,太老的驱动不支持太高的cuda),或者直接用CPU也可以编译,省钱。
- 需要选择系统为ubuntu 22.04的镜像
- 最好python也是3.10
- 内存在70G以上,太小了编译的时候会kill

- 选来选去发现有个miniconda的镜像符合,显卡选择的是A5000(或者用纯CPU),内置了cuda11.8和python3.10。除了这个,暂时没看到其他合适的。下面这个4090D最大支持cuda12.4,可以作为编译的底包,数据盘可以先扩容多10-50G,防止不够用。
- 基础镜像目前只有下面这一款Miniconda的镜像支持ubuntu 22.04/python3.10


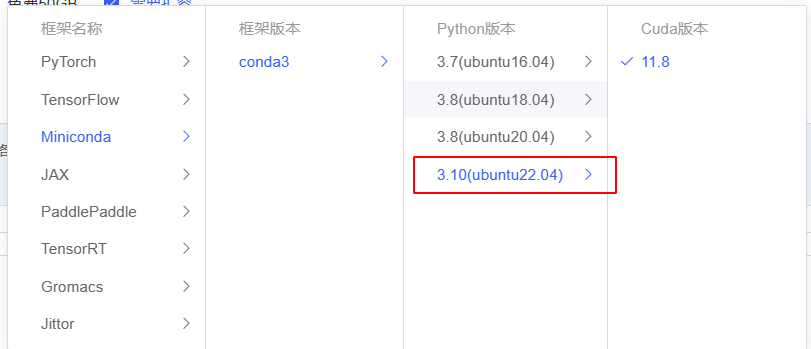
准备环境
- 建议到
~/autodl-tmp路径下面操作,这个地方不会占用系统空间。
安装cuda环境
- 下载cuda 12.3.2
wget https://developer.download.nvidia.com/compute/cuda/12.3.2/local_installers/cuda_12.3.2_545.23.08_linux.run- 给予可执行权限
chmod +x cuda_12.3.2_545.23.08_linux.run- 正式执行
./cuda_12.3.2_545.23.08_linux.run- 输入
accept,然后回车 - 按空格勾选或者取消勾选和上下方向键上下移动,只勾选
CUDA Toolkit 12.3,其他均取消勾选,然后选中Install即可。
CUDA Installer │
│ - [ ] Driver │
│ [ ] 545.23.08 │
│ + [X] CUDA Toolkit 12.3 │
│ [ ] CUDA Demo Suite 12.3 │
│ [ ] CUDA Documentation 12.3 │
│ - [ ] Kernel Objects │
│ [ ] nvidia-fs │
│ Options │
│ Install- 当出现“A symlink already exists at /usr/local/cuda. Update to this installation?”,输入
Yes确定更新cuda软连接。 - 再次确认cuda版本,看输出已经是cuda_12.3了
nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Wed_Nov_22_10:17:15_PST_2023
Cuda compilation tools, release 12.3, V12.3.107
Build cuda_12.3.r12.3/compiler.33567101_0- 删除安装包(可选)
rm cuda_12.3.2_545.23.08_linux.run- 删除已存在的cuda11.8(可选)
rm -rf /usr/local/cuda-11.8
rm -rf /usr/local/cuda-11- 修改环境,将cuda的include和extras/CPUTI目录都加到g++的默认头文件搜索路径
echo "export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/usr/local/cuda/extras/CUPTI/include:/usr/local/cuda/include" >> ~/.bashrc
echo "export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/usr/local/cuda/extras/CUPTI/include:/usr/local/cuda/include" >> /etc/profile
source /etc/profile
source ~/.bashrc
echo ${CPLUS_INCLUDE_PATH}安装cudnn,需要同时下载8.9.4.25(TensorRT需要)和9.0(不太清楚这个是否一定需要,可能是tritonserver需要)
- 去英伟达官网下载cudnn,可能需要登陆英伟达账号(邮箱/微信登陆,没有就注册一个)。官网链接:https://developer.nvidia.com/cudnn
- 由于系统也内置了cudnn,并且看样子是通过cudnn安装的,所以选择安装包的时候也选择Deb格式,用来覆盖旧版安装会更好。
- 查看命令如下
dpkg -l | grep cudnn
hi libcudnn8 8.6.0.163-1+cuda11.8 amd64 cuDNN runtime libraries
ii libcudnn8-dev 8.6.0.163-1+cuda11.8 amd64 cuDNN development librarie- 下载并安装cudnn 9.0
wget https://developer.download.nvidia.com/compute/cudnn/9.0.0/local_installers/cudnn-local-repo-ubuntu2204-9.0.0_1.0-1_amd64.deb
sudo dpkg -i cudnn-local-repo-ubuntu2204-9.0.0_1.0-1_amd64.deb
sudo cp /var/cudnn-local-repo-ubuntu2204-9.0.0/cudnn-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cudnn-cuda-12- 安装并下载cudnn8.9.4.25
sudo dpkg -i cudnn-local-repo-ubuntu2204-8.9.4.25_1.0-1_amd64.deb
sudo cp /var/cudnn-local-repo-ubuntu2204-8.9.4.25/cudnn-local-3C3A81D3-keyring.gpg /usr/share/keyrings/
cd /var/cudnn-local-repo-ubuntu2204-8.9.4.25/
sudo dpkg -i *.deb- 再次观察cudnn安装情况,目测已经ok
$dpkg -l | grep cudnn
ii cudnn-local-repo-ubuntu2204-8.9.4.25 1.0-1 amd64 cudnn-local repository configuration files
ii cudnn-local-repo-ubuntu2204-9.0.0 1.0-1 amd64 cudnn-local repository configuration files
ii cudnn9-cuda-12 9.0.0.312-1 amd64 NVIDIA cuDNN for CUDA 12
ii cudnn9-cuda-12-3 9.0.0.312-1 amd64 NVIDIA cuDNN for CUDA 12.3
ii libcudnn8 8.9.4.25-1+cuda12.2 amd64 cuDNN runtime libraries
ii libcudnn8-dev 8.9.4.25-1+cuda12.2 amd64 cuDNN development libraries and headers
ii libcudnn8-samples 8.9.4.25-1+cuda12.2 amd64 cuDNN samples
ii libcudnn9-cuda-12 9.0.0.312-1 amd64 cuDNN runtime libraries for CUDA 12.3
ii libcudnn9-dev-cuda-12 9.0.0.312-1 amd64 cuDNN development headers and symlinks for CUDA 12.3
ii libcudnn9-samples 9.0.0.312-1 all cuDNN samples
ii libcudnn9-static-cuda-12 9.0.0.312-1 amd64 cuDNN static libraries for CUDA 12.3- 删除安装包(可选)
rm -rf /var/cudnn-local-repo-ubuntu2204-9.0.0/
rm -rf /var/cudnn-local-repo-ubuntu2204-8.9.4.25/- 验证cudnn版本,可以看到只剩下8.9.4和9.0的cudnn了
$ldconfig -v | grep cudnn
libcudnn_adv_infer.so.8 -> libcudnn_adv_infer.so.8.9.4
libcudnn_adv_train.so.8 -> libcudnn_adv_train.so.8.9.4
libcudnn_cnn_infer.so.8 -> libcudnn_cnn_infer.so.8.9.4
libcudnn_cnn_train.so.8 -> libcudnn_cnn_train.so.8.9.4
libcudnn_ops_infer.so.8 -> libcudnn_ops_infer.so.8.9.4
libcudnn_ops_train.so.8 -> libcudnn_ops_train.so.8.9.4
libcudnn.so.8 -> libcudnn.so.8.9.4
libcudnn_heuristic.so.9 -> libcudnn_heuristic.so.9.0.0
libcudnn_engines_runtime_compiled.so.9 -> libcudnn_engines_runtime_compiled.so.9.0.0
libcudnn_cnn.so.9 -> libcudnn_cnn.so.9.0.0
libcudnn_engines_precompiled.so.9 -> libcudnn_engines_precompiled.so.9.0.0
libcudnn_adv.so.9 -> libcudnn_adv.so.9.0.0
libcudnn.so.9 -> libcudnn.so.9.0.0
libcudnn_ops.so.9 -> libcudnn_ops.so.9.0.0
libcudnn_graph.so.9 -> libcudnn_graph.so.9.0.0安装TensorRT
- 参考该文档
- 设置环境变量
export TRT_VER="9.2.0.5"
export CUDA_VER="12.3"
export CUDNN_VER="8.9.4.25-1+cuda12.2"
export NCCL_VER="2.19.3-1+cuda12.3"
export CUBLAS_VER="12.3.4.1-1"
export ARCH="x86_64"
export TRT_CUDA_VERSION="12.2"
export OS="linux"
export RELEASE_URL_TRT=https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/9.2.0/tensorrt-${TRT_VER}.${OS}.${ARCH}-gnu.cuda-${TRT_CUDA_VERSION}.tar.gz;- 下载TensorRT并且解压TensorRT
wget ${RELEASE_URL_TRT} -O /tmp/TensorRT.tar
tar -xf /tmp/TensorRT.tar -C /usr/local/- 移动解压后的文件到
/usr/local/tensorrt/目录,和官方容器保持一致,然后删除tensorrt的压缩包
mv /usr/local/TensorRT-${TRT_VER} /usr/local/tensorrt
rm -rf /tmp/TensorRT.tar- 配置ldconfig,然后lib可以被系统找到
echo "/usr/local/tensorrt/lib" > /etc/ld.so.conf.d/tensorrt.conf- 确定tensorrt版本是9.2.0
$ldconfig -v | grep nvinfer
libnvinfer_vc_plugin.so.9 -> libnvinfer_vc_plugin.so.9.2.0
libnvinfer_dispatch.so.9 -> libnvinfer_dispatch.so.9.2.0
libnvinfer.so.9 -> libnvinfer.so.9.2.0
libnvinfer_plugin.so.9 -> libnvinfer_plugin.so.9.2.0
libnvinfer_lean.so.9 -> libnvinfer_lean.so.9.2.0- 设置环境
echo "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/tensorrt/lib:/usr/local/cuda/lib64/" >> /etc/profile
echo "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/tensorrt/lib:/usr/local/cuda/lib64/" >> ~/.bashrc
source /etc/profile
source ~/.bashrc
# 测试lib库能否找到
echo ${LD_LIBRARY_PATH}
# 输出结果
# /usr/local/tensorrt/lib:/usr/local/cuda/lib64/- 安装tensorrt-python版
cd /usr/local/tensorrt/python
pip install tensorrt-9.2.0.post12.dev5-cp310-none-linux_x86_64.whl
pip install tensorrt_dispatch-9.2.0.post12.dev5-cp310-none-linux_x86_64.whl- 安装onnx_graphsurgeon(非常重要)
cd /usr/local/tensorrt/onnx_graphsurgeon
pip install onnx_graphsurgeon-0.4.0-py2.py3-none-any.whl安装pytorch2.1.0
- 根据这行代码,我们可以看出tensorrt-llm目前依赖于2.1.0的pytorch,编译tensorrt-llm的时候看到用到它了,提前安装一下
pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu121安装其他Pypi依赖
- TensorRT-LLM依赖:链接
- TensorRT-LLM 编译需要的依赖,链接
- 将这个txt下载下来再一次性安装
- 可以先注释第一个文件的第一行
--extra-index-url https://pypi.nvidia.com以及nvidia-ammo,这个会导致网络极慢。
pip install -r requirements.txt
pip install -r requirements-dev.txt
# 再补充几个网络下载不佳的,单独安装哈
pip install onnxruntime~=1.16.1 ninja- 再安装nvidia-ammo
pip install nvidia-ammo~=0.7.0 -i https://pypi.nvidia.com- 如果ammo下载不了,可以手动下载再传上去,下载地址
pip install ./nvidia_ammo-0.7.4-cp310-cp310-linux_x86_64.whl安装并测试mpi4py
- 安装
conda install mpi4py openmpi- 测试
$python3
Python 3.10.8 (main, Nov 24 2022, 14:13:03) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from mpi4py import MPI
>>> MPI.COMM_WORLD.Get_rank()
0
>>> MPI.COMM_WORLD.Get_size()
1安装DCGM用于gpu监控
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.deb
$ sudo dpkg -i cuda-keyring_1.0-1_all.deb
$ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /"
$ sudo apt-get update
$ sudo apt-get install -y datacenter-gpu-manager编译tritonserver
- 按照最上面的说法,我们需要编译triton 2.43。源码地址
- 编译方法,可以参考这个Build Without Docker
- 下载源码:
# 开启加速
source /etc/network_turbo
git clone https://github.com/triton-inference-server/server.git -b v2.43.0- 进入源码目录
cd server- 安装一些基本包,参考这一行代码
apt install curl libnuma-dev libre2-dev ca-certificates \
autoconf \
automake \
build-essential \
git \
gperf \
libre2-dev \
libssl-dev \
libtool \
libcurl4-openssl-dev \
libb64-dev \
libgoogle-perftools-dev \
patchelf \
zlib1g-dev \
libarchive-dev \
libxml2-dev \
git-lfs- 安装rapid_json
git clone https://github.com/miloyip/rapidjson.git
cd rapidjson
mkdir build
cd build
cmake ..
make -j10
sudo make install- 安装boost
wget https://ghproxy.net/https://github.com/boostorg/boost/releases/download/boost-1.84.0/boost-1.84.0.zip
unzip boost-1.84.0.zip
cd boost-1.84.0
mkdir build && cd build
cmake ..
make -j10
sudo make install- AutoDL自带的科学加速(看情况是否添加,加了有时候会异常)
- 开启
source /etc/network_turbo- 关闭
unset http_proxy && unset https_proxy- 设置tmp路径为当前路径,防止系统盘爆炸
mkdir /root/autodl-tmp/tmp
export TMPDIR=/root/autodl-tmp/tmp- 开始编译 python backend和tensorrt_llm的backend,并且将其安装到
/opt/tritonserver目录,注意tensorrt_llm分支是0.8.0,python的话,默认和triton一样即可,还需要一个ensemble后端做服务拼接
./build.py -v --no-container-build --build-dir=`pwd`/build --install-dir=/opt/tritonserver --enable-logging --enable-stats --enable-metrics --enable-gpu-metrics --enable-cpu-metrics --enable-tracing --enable-gpu --endpoint=grpc --endpoint=http --backend=ensemble --backend=tensorrtllm:v0.8.0 --backend=python- 顺便安装一下编译好的tensorrt-llm whl包,为后续编译engine做准备
cd /root/autodl-tmp/server/build/tensorrtllm/tensorrt_llm/build
pip install tensorrt_llm-0.8.0-cp310-cp310-linux_x86_64.whl
cd /opt/tritonserver/python
pip install tritonserver-2.43.0-py3-none-any.whl- 配置tritonserver环境
- 配置bin执行路径
echo "export PATH=$PATH:/opt/tritonserver/bin" >> /etc/profile
echo "export PATH=$PATH:/opt/tritonserver/bin" >> ~/.bashrc- 配置lib路径
echo "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/tritonserver/lib" >> /etc/profile
echo "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/tritonserver/lib" >> ~/.bashrc- 配置include路径
echo "export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/opt/tritonserver/include" >> ~/.bashrc
echo "export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/opt/tritonserver/include" >> /etc/profile- 应用
source /etc/profile
source ~/.bashrc- 测试tritonserver文件是否正常
tritonserver --help测试部署triton服务
- 下载源码
cd /root/autodl-tmp
# 开启加速
source /etc/network_turbo
# 下载本项目源码,main分支就是0.8.0
git clone https://github.com/Tlntin/Qwen-TensorRT-LLM.git
# 下载triton的tensorrtllm-backend作为启动源码
git clone https://github.com/triton-inference-server/tensorrtllm_backend.git -b v0.8.0- 下载好qwen1.5的模型,编译Engine
# 因为trt-llm内置的transformers版本较低(4.36.1),不支持qwen1.5,所以需要升级一下
pip install transformers -U
cd /root/autodl-tmp/Qwen-TensorRT-LLM/examples/qwen2
python3 build.py \
--paged_kv_cache \
--remove_input_padding \
--max_batch_size=2
# 测试一下
python3 run.py- 将本项目预定义好的triton配置文件复制一份过去
cd /root/autodl-tmp
cp Qwen-TensorRT-LLM/triton_model_repo/ -r tensorrtllm_backend/- 修改一下
tensorrtllm_backend/triton_model_repo里面的tokenizer_dir路径改成你现在的路径的,当前是/root/autodl-tmp/Qwen-TensorRT-LLM/examples/qwen2/qwen1.5_7b_chat。 - 将engine复制过去
cd /root/autodl-tmp/Qwen-TensorRT-LLM/examples/qwen2/trt_engines/fp16/1-gpu
cp -r ./* /root/autodl-tmp/tensorrtllm_backend/triton_model_repo/tensorrt_llm/1- 然后将
tensorrtllm_backend/triton_model_repo/tensorrt_llm里面的engine路径换成你现在的路径,也就是/root/autodl-tmp/tensorrtllm_backend/triton_model_repo/tensorrt_llm/1。 - 启动服务
cd ~/autodl-tmp/tensorrtllm_backend
python3 scripts/launch_triton_server.py --world_size=1 --model_repo=/root/autodl-tmp/tensorrtllm_backend/triton_model_repo
8. 另开一个终端,测试http请求
curl -X POST localhost:8000/v2/models/ensemble/generate \
-d '{"text_input": "<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n你好,你叫什么?<|im_end|>\n<|im_start|>assistant\n", "max_tokens": 100, "bad_words": "", "stop_words": "", "end_id": [151645], "pad_id": [151645]}'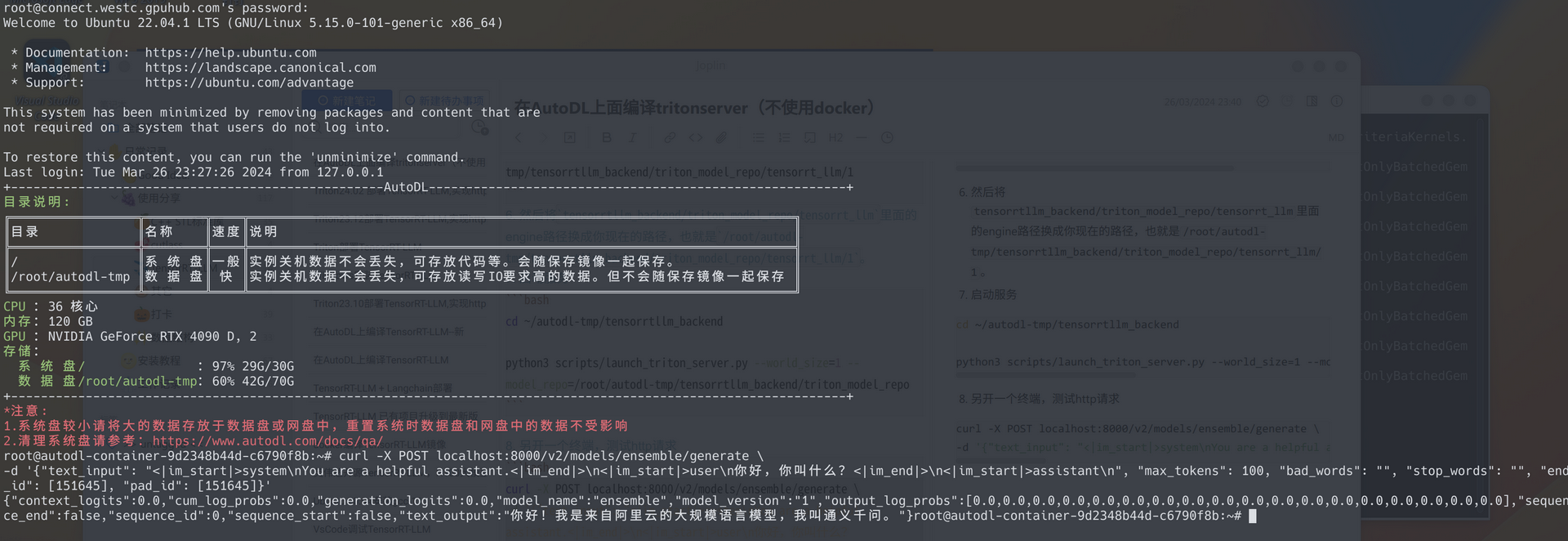
- 再测试一下http流式传输
curl -X POST localhost:8000/v2/models/ensemble/generate_stream \
-d '{"text_input": "<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n你好,你叫什么?<|im_end|>\n<|im_start|>assistant\n", "max_tokens": 100, "bad_words": "", "stop_words": "", "end_id": [151645], "pad_id": [151645], "stream": true}'